Social Distancing Detector using OpenCV
Written by Sanjeev Kumar and Saksham Bharwal

What is Social Distances ?
Social distancing, also called “physical distancing,” means keeping a safe space (stay at least 6 feet) between yourself and other people who are not from your household in both indoor and outdoor spaces.
The objective is to reduce transmission, reducing the size of the epidemic peak, and spreading cases over a longer time to relieve pressure on the healthcare system.
Social distancing aims to decrease or interrupt transmission of COVID-19 in a population by minimizing contact between potentially infected individuals and healthy individuals, or between population groups with high rates of transmission and population groups with no or low levels of transmission.

Computer Vision
Computer vision is a process by which we can understand the images and videos how they are stored and how we can manipulate and retrieve data from them. Computer Vision is the base or mostly used for Artificial Intelligence. Computer-Vision is playing a major role in self-driving cars, robotics as well as in photo correction apps.
OpenCV
OpenCV is the huge open-source library for the computer vision, machine learning, and image processing and now it plays a major role in real-time operation which is very important in today’s systems. By using it, one can process images and videos to identify objects, faces, or even handwriting of a human. When it integrated with various libraries, such as Numpuy, python is capable of processing the OpenCV array structure for analysis. To Identify image pattern and its various features we use vector space and perform mathematical operations on these features.
Object Detection using YOLO
The YOLO framework (You Only Look Once) deals with object detection in a different way, It takes the entire image in a single instance and predicts the bounding box coordinates and class probabilities for these boxes. The biggest advantage of using YOLO is its superb speed — it’s incredibly fast and can process 45 frames per second. YOLO also understands generalized object representation.
This is one of the best algorithms for object detection and has shown a comparatively similar performance to the R-CNN algorithms. In the upcoming sections, we will learn about different techniques used in YOLO algorithm.
- YOLO first takes an input image:

- The framework then divides the input image into grids (say a 3 X 3 grid):
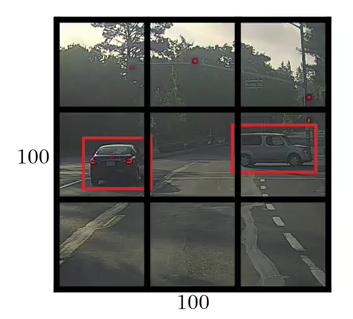
- Image classification and localization are applied on each grid. YOLO then predicts the bounding boxes and their corresponding class probabilities for objects (if any are found, of course).
We need to pass the labelled data to the model in order to train it. Suppose we have divided the image into a grid of size 3 X 3 and there are a total of 3 classes which we want the objects to be classified into. Let’s say the classes are Pedestrian, Car, and Motorcycle respectively. So, for each grid cell, the label y will be an eight dimensional vector:
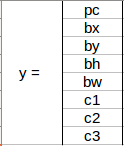
Here,
- pc defines whether an object is present in the grid or not (it is the probability)
- bx, by, bh, bw specify the bounding box if there is an object
- c1, c2, c3 represent the classes. So, if the object is a car, c2 will be 1 and c1 & c3 will be 0, and so on
Let’s say we select the first grid from the above example:

Since there is no object in this grid, pc will be zero and the y label for this grid will be:
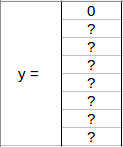
Here, ‘?’ means that it doesn’t matter what bx, by, bh, bw, c1, c2, and c3 contain as there is no object in the grid. Let’s take another grid in which we have a car (c2 = 1):

Before we write the y label for this grid, it’s important to first understand how YOLO decides whether there actually is an object in the grid. In the above image, there are two objects (two cars), so YOLO will take the mid-point of these two objects and these objects will be assigned to the grid which contains the mid-point of these objects. The y label for the centre left grid with the car will be:
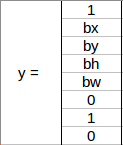
Since there is an object in this grid, pc will be equal to 1. bx, by, bh, bw will be calculated relative to the particular grid cell we are dealing with. Since car is the second class, c2 = 1 and c1 and c3 = 0. So, for each of the 9 grids, we will have an eight dimensional output vector. This output will have a shape of 3 X 3 X 8.
So now we have an input image and it’s corresponding target vector. Using the above example (input image — 100 X 100 X 3, output — 3 X 3 X 8), our model will be trained as follows:
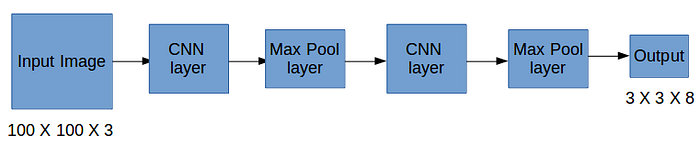
We will run both forward and backward propagation to train our model. During the testing phase, we pass an image to the model and run forward propagation until we get an output y.
Even if an object spans out to more than one grid, it will only be assigned to a single grid in which its mid-point is located. We can reduce the chances of multiple objects appearing in the same grid cell by increasing the more number of grids (19 X 19, for example).
Social Distance Detector using OpenCV , Deep learning and Computer Vision

The steps to build a social distancing detector include:
- Apply object detection to detect all people (and only people) in a video stream.
- Compute the pairwise distances between all detected people.
- Based on these distances, check to see if any two people are less than N pixels apart
This social distancing detector implementation will rely on pixel distances, which won’t necessarily be as accurate.
Detecting people in a video streams with OpenCV

We’ll be using the YOLO object detector with OpenCV to detect people in our video stream.

We begin with imports, including those needed — the NMS_THRESH and MIN_CONF . We’ll also take advantage of NumPy and OpenCV in this script. The script consists of a function definition for detecting people.

we define detect_people ; the function accepts four parameters:
- frame : The frame from your video file or directly from the webcam
- net : The pre-initialized and pre-trained YOLO object detection model
- ln : The YOLO CNN output layer names
- personIdx : The YOLO model can detect many types of objects; this index is specifically for the person class, as we won’t be considering other objects
Then grabs the frame dimensions for scaling purposes. We then initialize results list, which the function ultimately returns. The results consist of (1) the person prediction probability, (2) bounding box coordinates for the detection, and (3) the centroid of the object.
Given the frame , now it is time to perform inference with YOLO:

Pre-processing the frame requires that we construct a blob . From there, we are able to perform object detection with YOLO and OpenCV .
for output in layerOutputs:
for detection in output:
scores = detection[5:]
classID = np.argmax(scores)
confidence = scores[classID] if classID == personIdx and confidence > MIN_CONF:
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height) = box.astype("int") x = int(centerX - (width / 2))
y = int(centerY - (height / 2)) boxes.append([x, y, int(width), int(height)])
centroids.append((centerX, centerY))
confidences.append(float(confidence))
Looping over each of the layerOutputs and detections , we first extract the classID and confidence (i.e., probability) of the current detected.
From there, we verify that (1) the current detection is a person and (2) the minimum confidence is met or exceeded.
Assuming so, we compute bounding box coordinates and then derive the center (i.e., centroid) of the bounding box . Notice how we scale (i.e., multiply) our detection by the frame dimensions we gathered earlier.
Using the bounding box coordinates, then derive the top-left coordinates for the object.
We then update each of our lists ( boxes , centroids, and confidences).
Next, we apply non-maxima suppression:
idxs = cv2.dnn.NMSBoxes(boxes, confidences, MIN_CONF, NMS_THRESH)if len(idxs) > 0:for i in idxs.flatten():(x, y) = (boxes[i][0], boxes[i][1])(w, h) = (boxes[i][2], boxes[i][3])r = (confidences[i], (x, y, x + w, y + h), centroids[i])results.append(r)return results
The purpose of non-maxima suppression is to suppress weak, overlapping bounding boxes. Appling this method (it is built-in to OpenCV) and results in the idxs of the detections.
Assuming the result of NMS yields at least one detection, we loop over them, extract bounding box coordinates, and update our results list consisting of the:
- Confidence of each person detection
- Bounding box of each person
- Centroid of each person
Finally, we return the results to the calling function.
Implementing the Social Distancing Detector

The most notable imports include the config, detect_people function, and the Euclidean distance metric (shortened to dist and to be used to determine the distance between centroids).
To handle the command line arguements :

This script requires the following arguments to be passed via the command line/terminal:
- — input : The path to the video file. If no video file path is provided, your computer’s first webcam will be used by default.
--output: The path to an output (i.e., processed) video file.--display: By default, it display the social distance application on-screen as we process each frame. Alternatively, you can set this value to 0 to process the stream in the background.
labelsPath = os.path.sep.join([config.MODEL_PATH, “coco.names”])LABELS = open(labelsPath).read().strip().split(“\n”)weightsPath = os.path.sep.join([config.MODEL_PATH, “yolov3.weights”])configPath = os.path.sep.join([config.MODEL_PATH, “yolov3.cfg”])
Here, we load the COCO labels as well as define the YOLO paths .
Using the YOLO paths, now we can load the model into memory:
print(“[INFO] loading YOLO from disk…”)net = cv2.dnn.readNetFromDarknet(configPath, weightsPath)if config.USE_GPU:print(“[INFO] setting preferable backend and target to CUDA…”)net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
Using OpenCV’s DNN module, we load our YOLO net into memory. If you have the USE_GPU option set in the config, then the backend processor is set to be your NVIDIA CUDA-capable GPU. If you don’t have a CUDA-capable GPU, ensure that the configuration option is set to False so that your CPU is the processor used.

Here, we gather the output layer names from YOLO; we’ll need them in order to process our results. We then start our video stream (either a video file via the — input command line argument or a webcam stream) .
Finally, we’re ready to begin processing frames and determining if people are maintaining safe social distance:
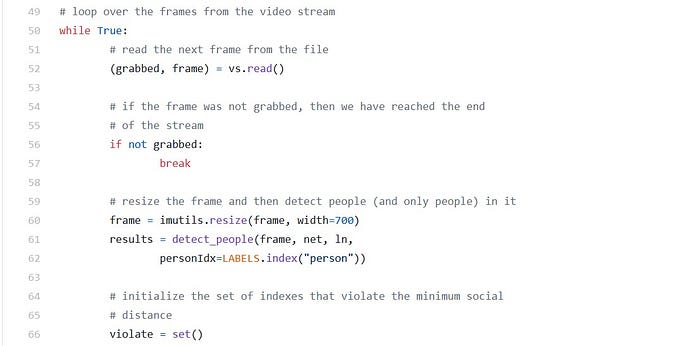
The dimensions of our input video for testing are quite large, so we resize each frame while maintaining aspect ratio.
Using the detect_people function implemented in the previous section, we grab results of YOLO object detection . If you need a refresher on the input parameters required or the format of the output results for the function call, be sure to refer to the listing in the previous section.
We then initialize our violate set on this set maintains a listing of people who violate social distance regulations set forth by public health professionals.
We’re now ready to check the distances among the people in the frame:
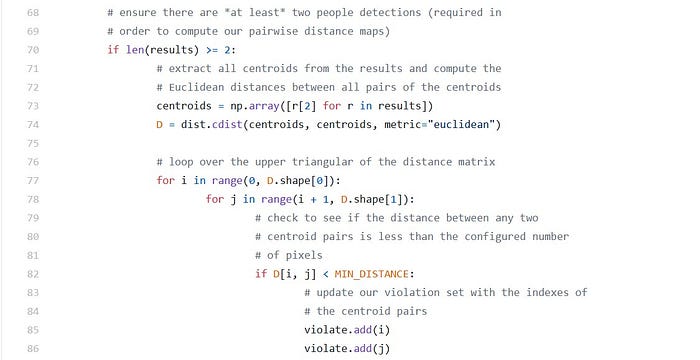
Assuming that at least two people were detected in the frame, we proceed to:
- Compute the Euclidean distance between all pairs of centroids
- Loop over the upper triangular of distance matrix (since the matrix is symmetrical)
- Check to see if the distance violates our minimum social distance set forth by public health professionals. If two people are too close, we add them to the violate set.
So let’s annotate the frame with rectangles, circles, and text to visualize results :
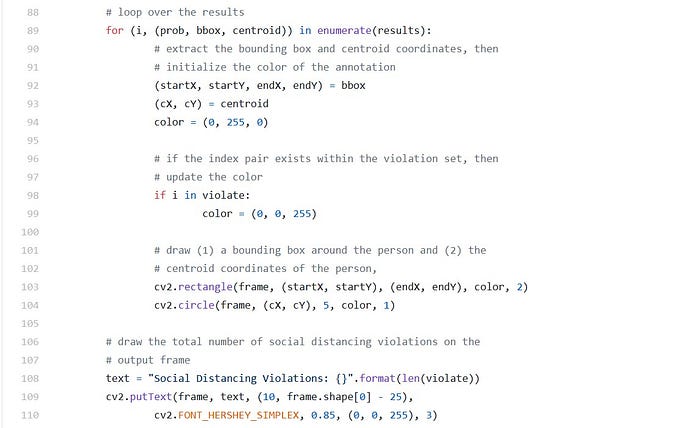
Looping over the results , we proceed to:
- Extract the bounding box and centroid coordinates
- Initialize the color of the bounding box to green
- Check to see if the current index exists in the violate set, and if so, update the color to red
- Draw both the bounding box of the person and their object centroid. Each is color-coordinated, so we’ll see which people are too close.
- Display information on the total number of social distancing violations (the length of the violate set) .
Social distancing detector results :
To see the results open up a terminal, and execute the following command:

Here, we can see that our social distancing detector is correctly marking people red who violate social distancing rules.
Code for this project can be found here
Furthur Scope and Improvements
This social distancing detector did not leverage a proper camera calibration, meaning that we could not (easily) map distances in pixels to actual measurable units (i.e., meters, feet, etc.).
Therefore, the first step to improving our social distancing detector is to utilize a proper camera calibration. Doing so will yield better results and enable you to compute actual measurable units (rather than pixels).